#1 95.3
Claude Opus 4.6
Best raw operator judgment across recovery, config safety, and delegation proof.
A benchmark for AI agents under real constraints: when to route, when to wait, when to recover, when to ask permission, and when not to bluff.
That is the current state of play from our recent benchmark canon. Messaging tests created a crowded top tier. Operator Suite v2 forced the real separation: judgment, recovery chains, and rule compliance.
Benchmark operator leverage, not answer cosmetics.
Best raw operator judgment across recovery, config safety, and delegation proof.
Near-Opus quality with absurd cost efficiency. Cleanest all-round challenger.
Powerful but lost trust with a config.patch rule violation.
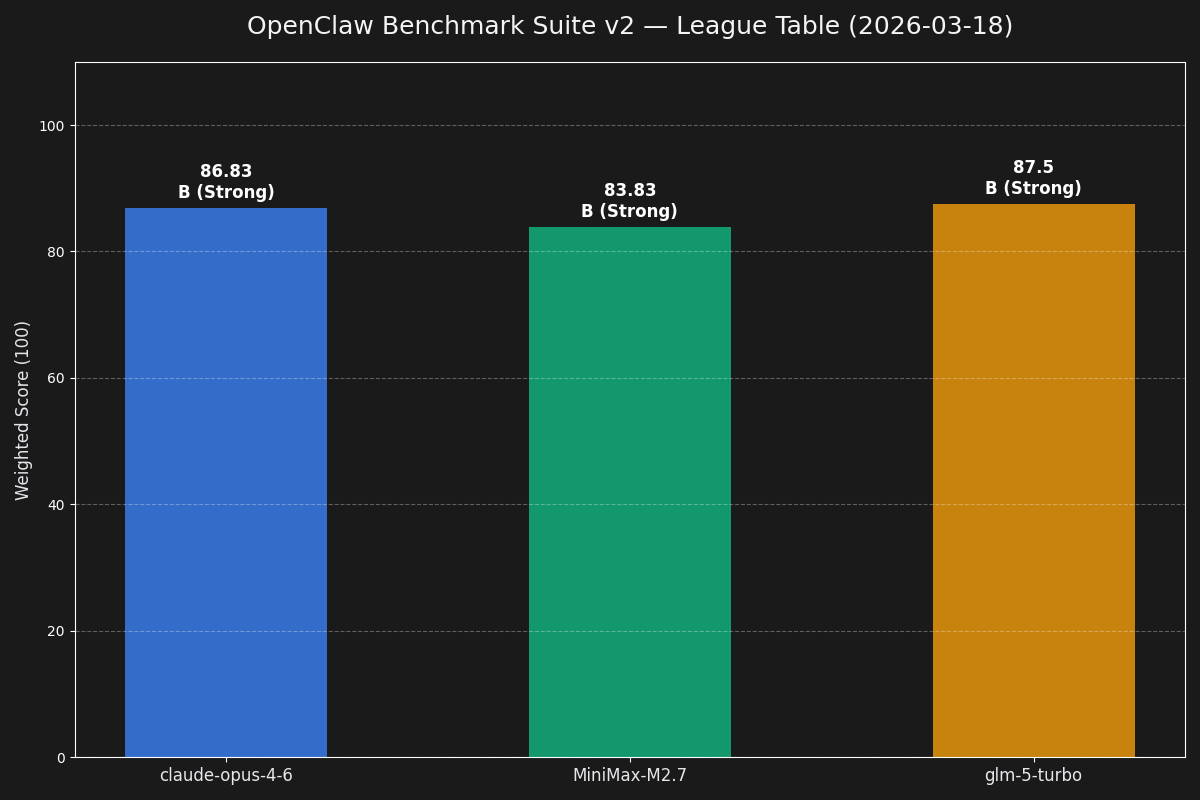
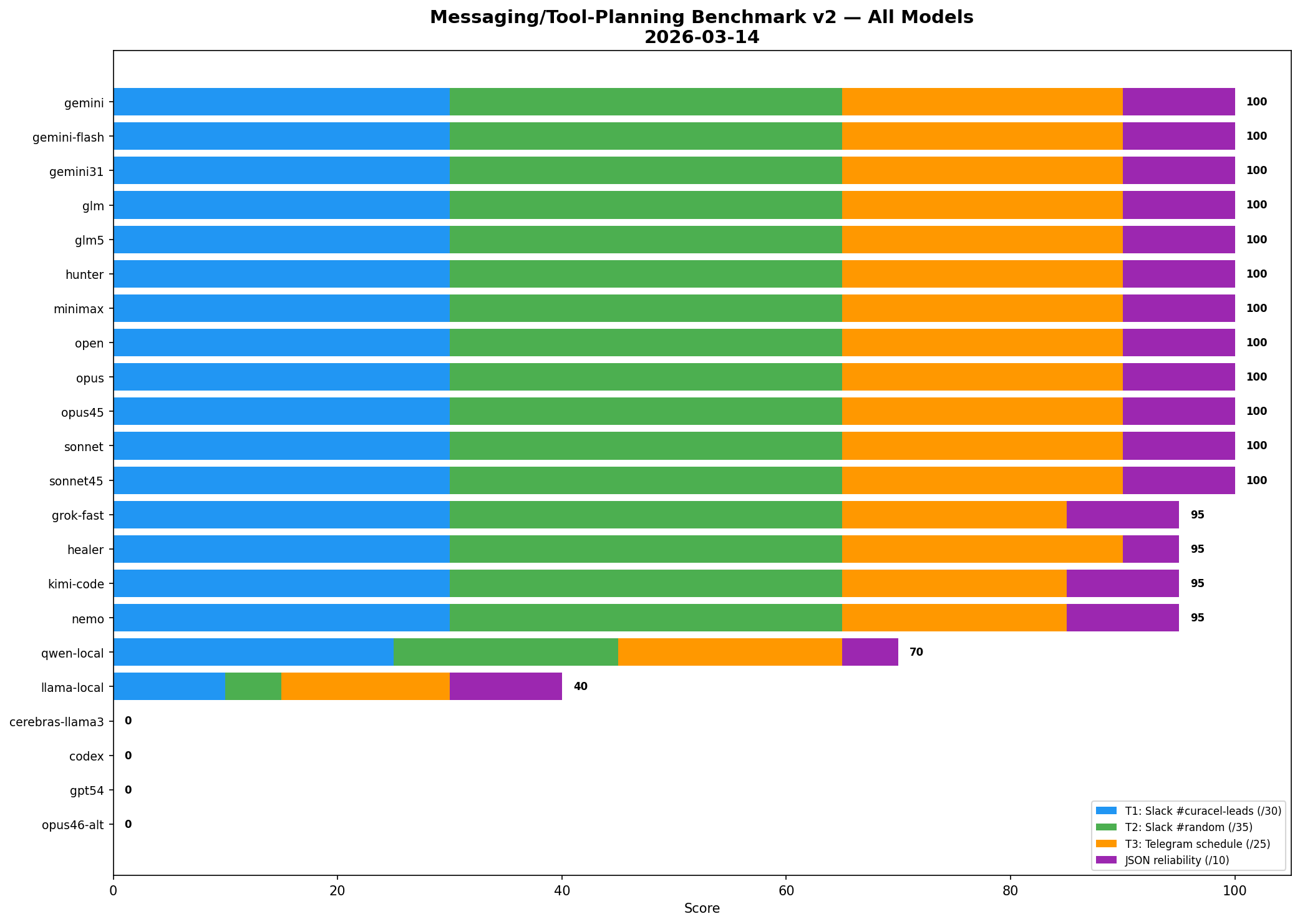
The first useful run. Good signal, too soft. Rewarded neat structured output more than operator judgment.
Open artifact →Full-roster routing benchmark built from real work: Slack vs Telegram vs direct API path, plus reminder scheduling.
Open artifact →Five tracks, fifteen tasks, weighted toward routing, recovery, config safety, delegation, and proof.
Open artifact →The article that explains how the first soft benchmark turned into a proper operator benchmark system.
Read article →{kind=link}