Benchmarks That Actually Matter for AI Agents
We started with a soft benchmark that rewarded pretty JSON. Then we tightened the constraints, forced proof, batched the full roster, and built a benchmark system that can actually change model-routing decisions.

The benchmark started the way a lot of useful work starts: with a slightly dangerous casual question.
We had just added four new models for cron and background work, and the obvious next step was to see whether they were actually any good or just wearing impressive shoes.
That kicked off a 24-hour benchmarking sprint that went through four stages:
- A first benchmark that was useful, but too soft
- A second benchmark based on real messaging tasks
- A hard benchmark pack built around hidden constraints, failure recovery, and proof
- A full benchmark suite designed to evaluate operator leverage, not output cosmetics
The punchline: the benchmark system got better faster than the models did.
How it started: test the four new cron models
The first benchmark was focused on a practical question:
Which of the new background-worker models can be trusted for cron-style work?
So we built a small benchmark around three cron-adjacent tasks:
- Quiet hours filtering — should this wake Henry up or wait?
- Slack triage — what gets surfaced now, held till morning, or ignored?
- Action extraction — can the model pull out owners, deadlines, and follow-ups reliably?
- JSON reliability — does it return valid structured output on the first pass?
That first run gave us a useful ranking:
- Hunter — 94/100
- Healer — 90/100
- Open — 87/100
- Nemo — 87/100
Not bad. Useful signal. But still not enough.
First benchmark image

The problem became obvious almost immediately: this benchmark still rewarded models for being neat, compliant, and good at structured extraction.
That matters.
But it does not tell you whether a model can operate inside a real environment without making expensive mistakes.
Second iteration: benchmark real messaging and tool planning
So the next benchmark got more grounded.
Instead of synthetic tasks, we used actual work from the week:
- sending a Slack message to Kabiru in
#curacel-leads, cc Chi - posting the CTRL article to Slack
#randomwhile tagging@engr - scheduling a one-off Telegram reminder for an event
The benchmark tested whether a model could choose the right action path when the obvious tool was wrong.
That detail matters.
In our setup, a Telegram-bound session cannot just use the session message tool to post into Slack. The correct answer is to recognize the routing constraint and use the direct Slack API path instead.
That benchmark was better than the first one, but it exposed a second issue:
too many strong models scored near-perfect.
Which meant we had improved the benchmark, but we still had not made it hard enough.
Messaging benchmark v1 image

The real constraint: we were benchmarking syntax, not judgment
Once we stepped back, the flaw was obvious.
We were still giving too much credit for:
- valid JSON
- tidy parameter passing
- obvious tool naming
- clean extraction from an explicit prompt
That is useful, but it is not the same thing as operator competence.
A genuinely good agent benchmark needs to stress:
- hidden constraints
- tool/runtime selection under ambiguity
- failure recovery
- proof before claiming done
- the ability to not act when the right move is restraint
So we turned the benchmark inside out.
Hard benchmark pack v1
The next move was to build a proper hard benchmark pack from real incidents in the workspace.
We used tasks grounded in actual failures and decisions from the week:
- Quiet-hours triage — not everything should wake Henry up
- Tool/runtime path selection — direct Slack API vs blocked session message path
- Provider vs model failure diagnosis — if a provider returns 429 or the harness breaks, don’t blame the model like an idiot
- Hidden constraints — email verification rules, approval rules, sub-agent restrictions
- Self-heal + checkpoint behavior — resume correctly, skip completed phases, require proof
That became:
2026-03-13-hard-benchmark-pack-v1/
This was the first benchmark pack designed to test what actually creates leverage in production.
Full-roster run: the first all-model attempt was too generous
Then came the full-roster messaging run.
And this part mattered because it caught one of the most common benchmark failure modes:
the benchmark itself lying to you.
An early all-model attempt looked too clean. It was generous. Suspiciously generous.
One of the clearest tells was a tiny local model looking far more competent than it had any right to be on tool naming and ID fidelity. That is the benchmarking equivalent of a three-legged horse winning the Grand National.
So the run was rebuilt the right way:
- models were run in batches
- raw outputs were persisted after each batch
- scoring happened before chart generation
- failures were classified as model, provider, harness, or context failures
That produced the canonical verified messaging benchmark pack:
messaging-tool-planning-full-batched-v2/
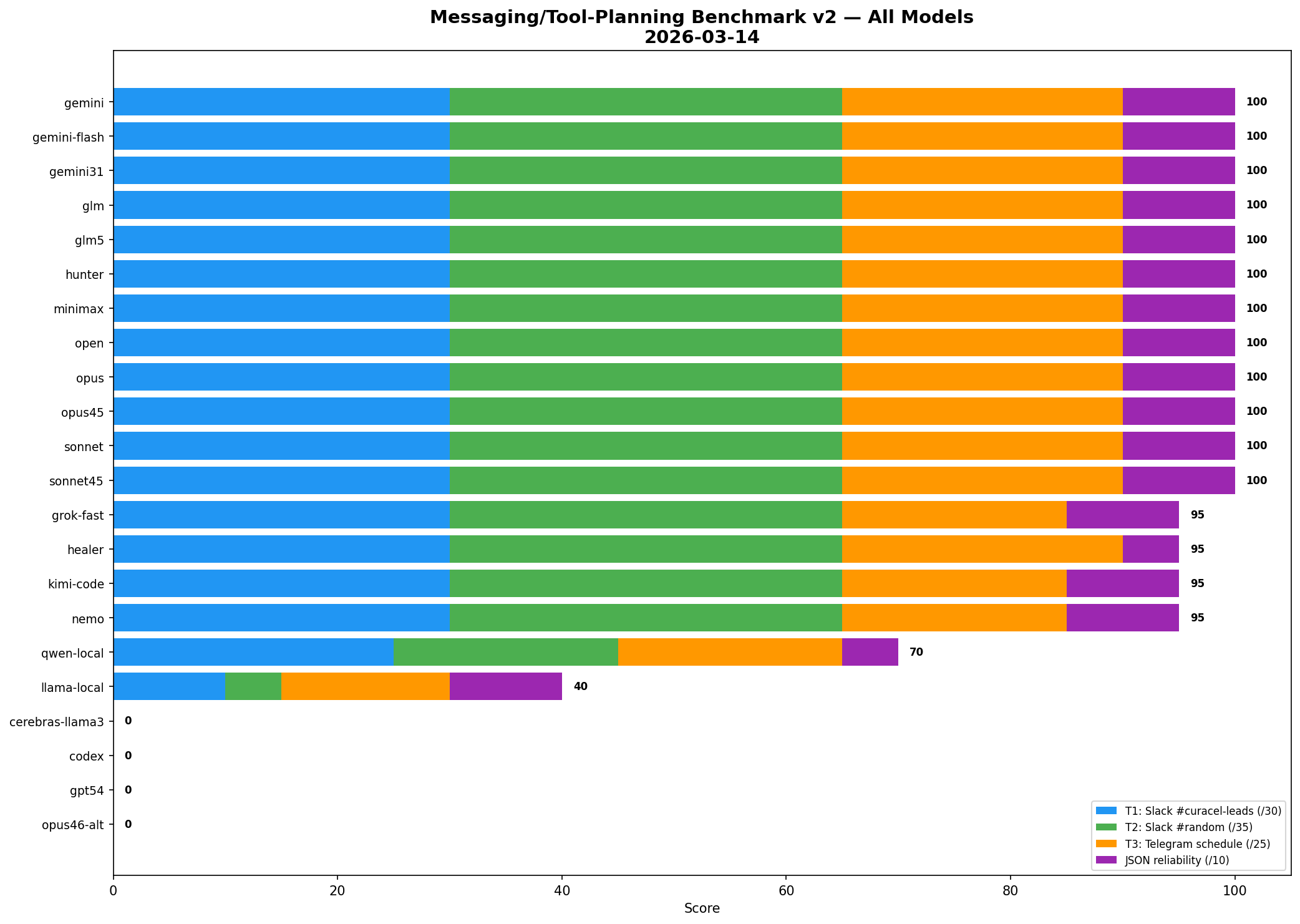
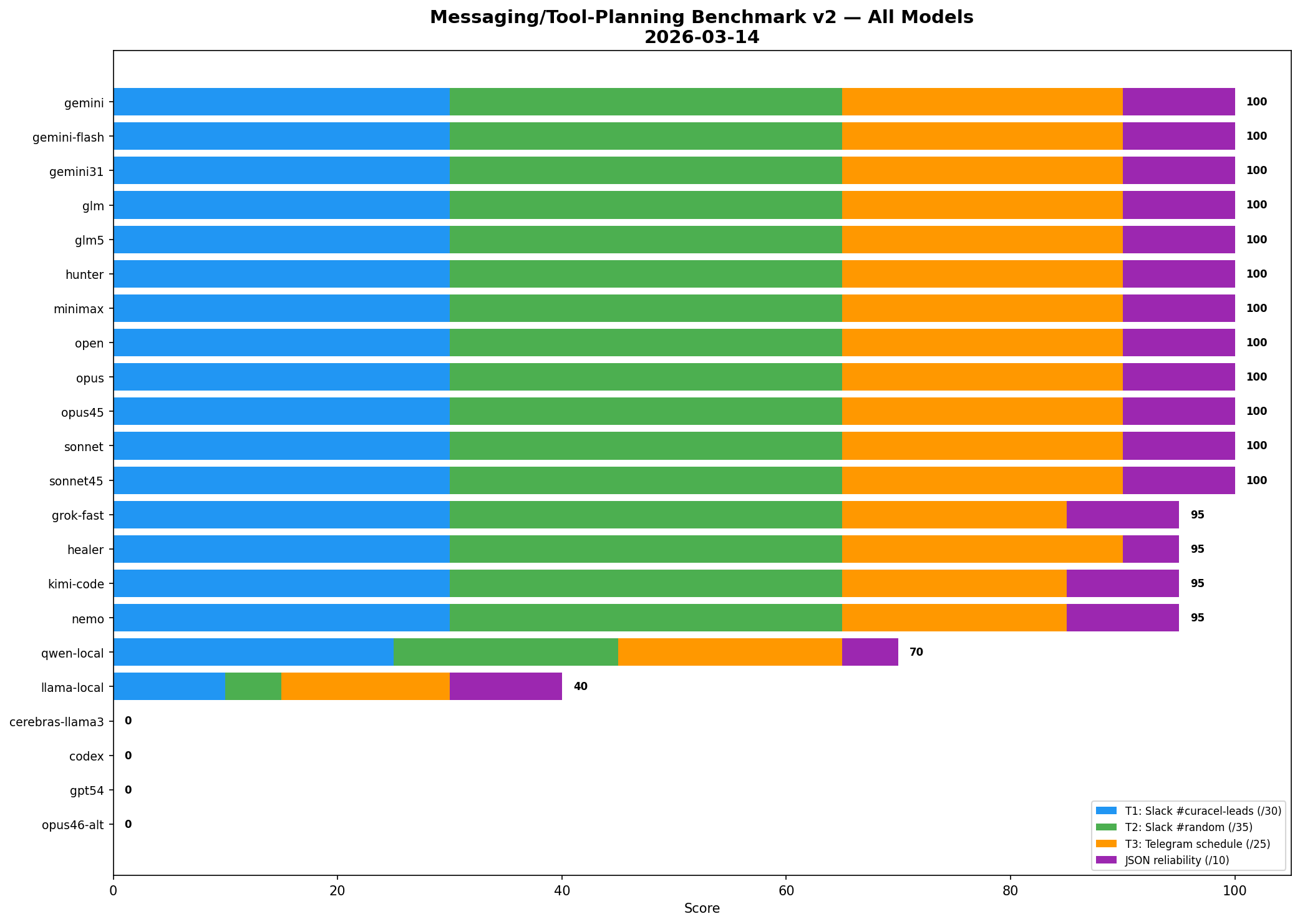
Final verified full-roster result
The verified run tested 22 models.
What happened
12 models scored 100/100
- Gemini Pro
- Gemini Flash
- Gemini 3.1
- GLM-4.7
- GLM-5
- Hunter
- MiniMax
- Open
- Opus 4.6
- Opus 4.5
- Sonnet 4.6
- Sonnet 4.5
4 models scored 95/100
- Grok Fast
- Healer
- Kimi Code
- Nemo
Local models got exposed
- qwen-local — 70/100
- llama-local — 40/100
And several models could not be fairly scored in that harness because the issue was not reasoning quality but infrastructure pathing:
- GPT-5.3 Codex — provider unsupported by the benchmark path we used
- GPT-5.4 — same issue
- Cerebras Llama — context window too small
- Opus 4.6 alt ID — 404 path problem
Final league table
The meta-lesson: benchmark packs need their own standards
At this point it was clear we were no longer just running benchmarks.
We were building a benchmark operating system.
So we standardized it.
Benchmarking context
A reusable workspace context file was created to preserve:
- benchmark philosophy
- artifact structure
- failure taxonomy
- batch-run protocol
- canonical benchmark packs
- lessons learned from bad runs
Public benchmarking skill
The workflow itself was then turned into a reusable public skill:
- Enterprise Crew Skills repo: benchmarking skill
The point was simple: future benchmark work should start from a system, not from memory and caffeine.
Benchmark Suite v2: operator leverage, not pretty answers
The final step was to design Benchmark Suite v2.
This is the version that stops pretending a clean JSON blob means a model can run real work.
It has 5 tracks × 3 tasks = 15 tasks, weighted toward actual operator behavior:
- Slack Triage + Quiet Hours v2
- Tool Routing Under Constraints
- Failure Recovery / Self-Heal
- Config Safety + Docs-First
- Agent Delegation + Proof
The key design change is this:
- syntax is capped at a small slice of the score
- judgment carries the weight
That means a model should lose hard for:
- choosing the wrong runtime
- missing buried constraints
- failing to verify
- blaming the model for a provider failure
- claiming done without proof
- acting when the correct answer is to wait
That is the kind of benchmark that can actually change routing decisions.
What changed because of this work
This was not benchmark theatre.
It changed real model assumptions:
- the first all-model league table was discarded as too generous
- the canonical full-roster messaging benchmark is now the batched v2 run
- local small models are clearly weaker at tool naming, ID fidelity, and retry stability
- GPT/Codex models are still unresolved in this benchmark path because the provider route itself blocked fair evaluation
- the benchmark system now has a reusable public skill and a suite spec for harder evaluations
The real benchmark question
The useful question is no longer:
Which model writes the prettiest answer?
It is:
Which model can operate inside a real environment, under constraints, recover from failure, and prove it actually finished the work?
That is the benchmark worth running.
And, more importantly, it is the benchmark worth trusting.