Agent Reliability Scorecard
A seven-day production telemetry scorecard comparing Book, Ada, Spock, Zora, Scotty, and smaller OpenClaw profiles by agent identity instead of collapsing them into one runtime average.

This is the corrected version of the reliability report.
The first pass collapsed one Hermes operator and a multi-agent OpenClaw fleet into two runtime buckets. That was useful for finding a problem, but it was not the clean comparison. The cleaner comparison is agent by agent.
So this version removes the framework-war framing and shows the production numbers across agents:
- Book on Hermes.
- Ada on OpenClaw.
- Spock on OpenClaw.
- Zora on OpenClaw.
- Scotty on OpenClaw.
- Smaller OpenClaw local and Midas slices are kept visible instead of hidden.
TL;DR
- Observation window: 2026-05-09 13:41:58 UTC to 2026-05-16 13:42:28 UTC.
- Unit of comparison: agent identity.
- Data source: production telemetry, not synthetic prompts.
- Status labels:
success,fail,unknown. - Known-session success:
success / (success + fail). - Unknown sessions are shown separately and are not counted as success.
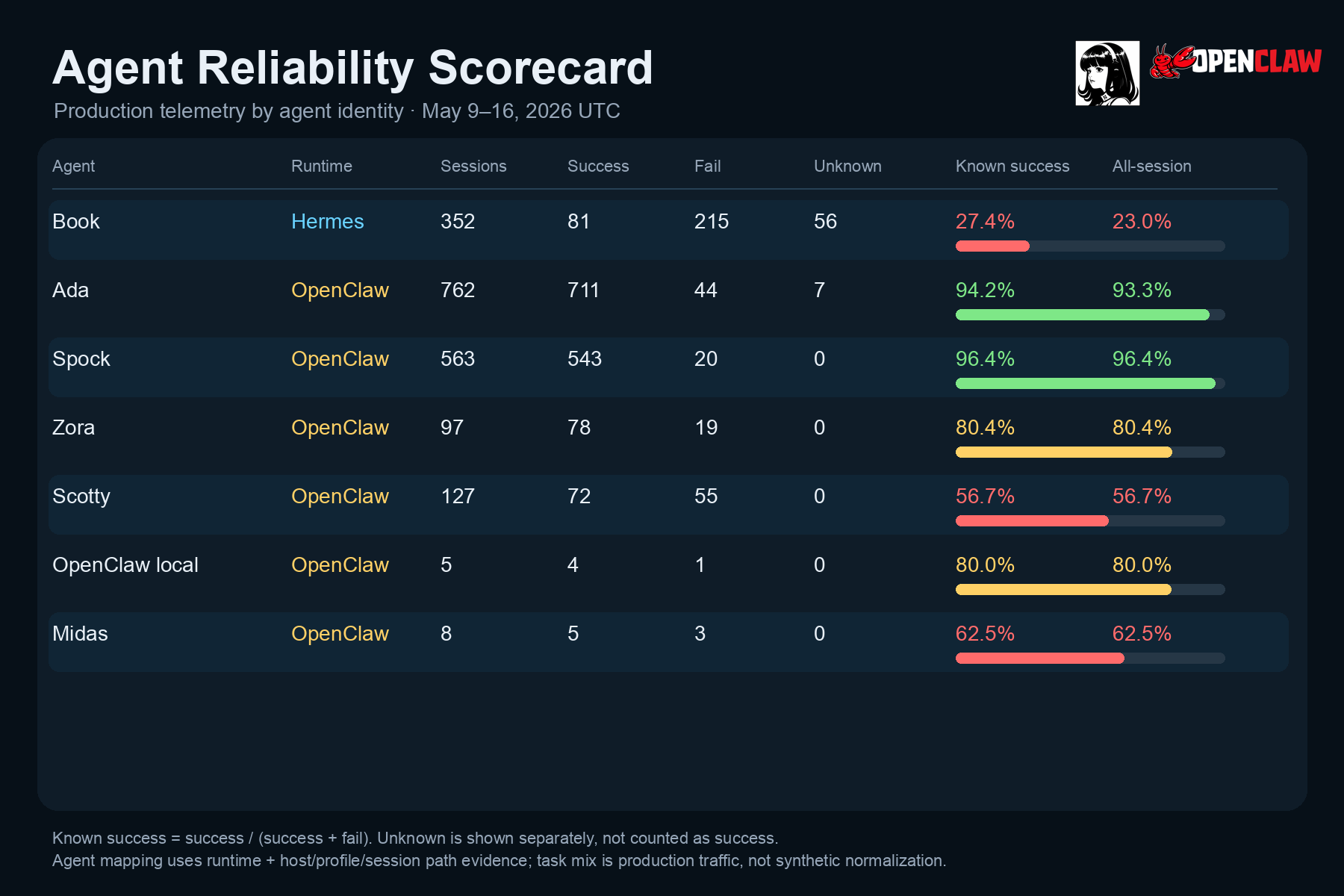
- Best large-volume agent: Spock, 563 sessions, 96.4% known-session success.
- Highest-volume agent: Ada, 762 sessions, 94.2% known-session success.
- Lowest large-volume agent: Book, 352 sessions, 27.4% known-session success.
- Worst OpenClaw agent slice: Scotty, 127 sessions, 56.7% known-session success.
Agent scorecard
| Agent | Runtime | Sessions | Success | Fail | Unknown | Known sessions | Known success | All-session success |
|---|---|---|---|---|---|---|---|---|
| Book | 352 | 81 | 215 | 56 | 296 | 27.4% | 23.0% | |
| Ada |  OpenClaw OpenClaw | 762 | 711 | 44 | 7 | 755 | 94.2% | 93.3% |
| Spock | OpenClaw | 563 | 543 | 20 | 0 | 563 | 96.4% | 96.4% |
| Zora | OpenClaw | 97 | 78 | 19 | 0 | 97 | 80.4% | 80.4% |
| Scotty | OpenClaw | 127 | 72 | 55 | 0 | 127 | 56.7% | 56.7% |
| OpenClaw local | OpenClaw | 5 | 4 | 1 | 0 | 5 | 80.0% | 80.0% |
| Midas | OpenClaw | 8 | 5 | 3 | 0 | 8 | 62.5% | 62.5% |
Agent mapping
The comparison uses agent identity first. Runtime is only metadata beside the agent.
| Agent | Runtime | Mapping evidence | Hosts / profiles |
|---|---|---|---|
| Book | Hermes | Hermes session store on mac.lan | mac.lan |
| Ada | OpenClaw | ada-gateway OpenClaw sessions, including main, cron-pi, and asym raw agent ids | ada-gateway |
| Spock | OpenClaw | spock-gateway OpenClaw sessions excluding the Midas profile slice | spock-gateway |
| Zora | OpenClaw | .openclaw-zora profiles and /agents/zora/ session paths | MascotM3, mac.lan |
| Scotty | OpenClaw | castlemascot-r1, /home/jamify/.openclaw, and mc-auto-scotty session evidence | castlemascot-r1 |
| OpenClaw local | OpenClaw | Small local OpenClaw sessions not cleanly attributable to one named crew agent | mac.lan, MascotM3 |
| Midas | OpenClaw | .openclaw-midas profile/session evidence | spock-gateway |
What the numbers say
| Rank by known success | Agent | Runtime | Sessions | Known success | Failures | Unknown |
|---|---|---|---|---|---|---|
| 1 | Spock | OpenClaw | 563 | 96.4% | 20 | 0 |
| 2 | Ada | OpenClaw | 762 | 94.2% | 44 | 7 |
| 3 | Zora | OpenClaw | 97 | 80.4% | 19 | 0 |
| 4 | OpenClaw local | OpenClaw | 5 | 80.0% | 1 | 0 |
| 5 | Midas | OpenClaw | 8 | 62.5% | 3 | 0 |
| 6 | Scotty | OpenClaw | 127 | 56.7% | 55 | 0 |
| 7 | Book | Hermes | 352 | 27.4% | 215 | 56 |
The main point is not “Hermes vs OpenClaw.”
The main point is that agent identity changes the picture:
- Spock and Ada were high-volume, high-success OpenClaw agents.
- Scotty was a clear OpenClaw outlier.
- Zora was middling and lower-volume.
- Book/Hermes had the weakest final-session outcome in this window.
- A runtime-level average would hide the difference between Ada/Spock and Scotty.
Small-sample rows
Midas and OpenClaw local are shown because hiding them would make the table look cleaner than the telemetry. They should not drive the headline.
| Agent slice | Sessions | How to read it |
|---|---|---|
| Midas | 8 | Useful for completeness, too small for a broad reliability claim. |
| OpenClaw local | 5 | Kept separate because the session evidence was not cleanly attributable to one named crew agent. |
Methodology
The public JSON behind this article is here: agent-results-summary.json.
The collector classified each session into one of three labels:
| Label | Meaning |
|---|---|
success | An assistant/text response was observed and no explicit structured failure marker controlled the final outcome. |
fail | A structured runtime/tool/provider failure marker was present, or user input had no assistant response. |
unknown | The session existed, but the available artifact did not provide enough signal for a trustworthy final label. |
This is production telemetry. It does not normalize task type, task difficulty, model route, or human satisfaction. It answers a narrower question:
In this seven-day slice, which agent sessions ended cleanly, failed, or remained unresolved?
Model route coverage
The first scorecard did not spell this out clearly enough: model-route coverage is uneven across the two runtimes.
Hermes session telemetry captured model names. The OpenClaw session metadata harvested for this seven-day slice did not include model route, so OpenClaw rows are marked as unknown/not captured in the public JSON instead of pretending we know.
| Agent | Model route observed in harvested telemetry | Read |
|---|---|---|
| Book | gpt-5.5: 159 · MiniMax-M2.7: 99 · glm-4.7: 84 · smaller routes: 10 | Model route captured directly by Hermes session metadata. |
| Ada | unknown/not captured: 762 | OpenClaw session metadata did not expose model route in this harvest. |
| Spock | unknown/not captured: 563 | Same limitation. |
| Zora | unknown/not captured: 97 | Same limitation. |
| Scotty | unknown/not captured: 127 | Same limitation. |
So: this post compares observed session outcomes by agent. It does not claim the agents were using equivalent model routes.
Failed-session shape
The harvested data also does not fully normalize task type. For Book/Hermes, source and some titles were captured. For OpenClaw, this harvest mostly preserved session files, hosts, profiles, status, and failure markers, but not user-facing task titles.
That means the safest public breakdown is failure shape, not full intent taxonomy.
| Agent | Failed sessions | Failed-session source / task coverage | Top failure shapes |
|---|---|---|---|
| Book | 215 | cron: 113 · telegram: 62 · cli: 22 · discord: 18 | no assistant response/unresolved: 95 · timeout: 57 · auth/permission: 24 · config/plugin drift: 19 · rate limit: 14 |
| Ada | 44 | unknown/not captured: 44 | timeout: 22 · provider/model/API mismatch: 10 · auth/permission: 6 · config/plugin drift: 4 |
| Spock | 20 | unknown/not captured: 20 | timeout: 11 · rate limit: 6 · config/plugin drift: 2 · auth/permission: 1 |
| Zora | 19 | unknown/not captured: 19 | timeout: 17 · config/plugin drift: 1 · other/unclear: 1 |
| Scotty | 55 | unknown/not captured: 55 | timeout: 21 · auth/permission: 16 · rate limit: 14 · provider/model/API mismatch: 4 |
The public JSON now carries these fields per agent:
model_distributionfailed_model_distributionfailed_source_distributionfailed_session_failure_kinds
Final read
The corrected read is simple:
- Do not compare Book against a whole OpenClaw fleet average.
- Compare Book, Ada, Spock, Zora, Scotty, and smaller slices directly.
- Put the runtime icon beside the agent, but keep the agent as the row.
- Treat framework-level aggregation as secondary.
That is the more honest scorecard. Less dramatic. More useful.