
Enterprise oMLX
2026-04-25
Qwen 3.6 27B local quant trio
NVFP4 40/100 · MXFP4 40/100 · 4bit 20/100
First live oMLX benchmark pass for the three Qwen3.6-27B Apple Silicon variants. They are now served in OpenClaw and on Benchboard, but this run is weak enough that routing should not trust them yet without a rerun/tuning pass.

PrismML local benchmark
2026-04-16
PrismML Bonsai 1.7B
56/100 · avg 8.8s · CPU quick pack
Official PrismML Bonsai demo run through the same quick operator pack. Fine for lightweight local use, but it missed the routing task badly and is not an OpenClaw default.
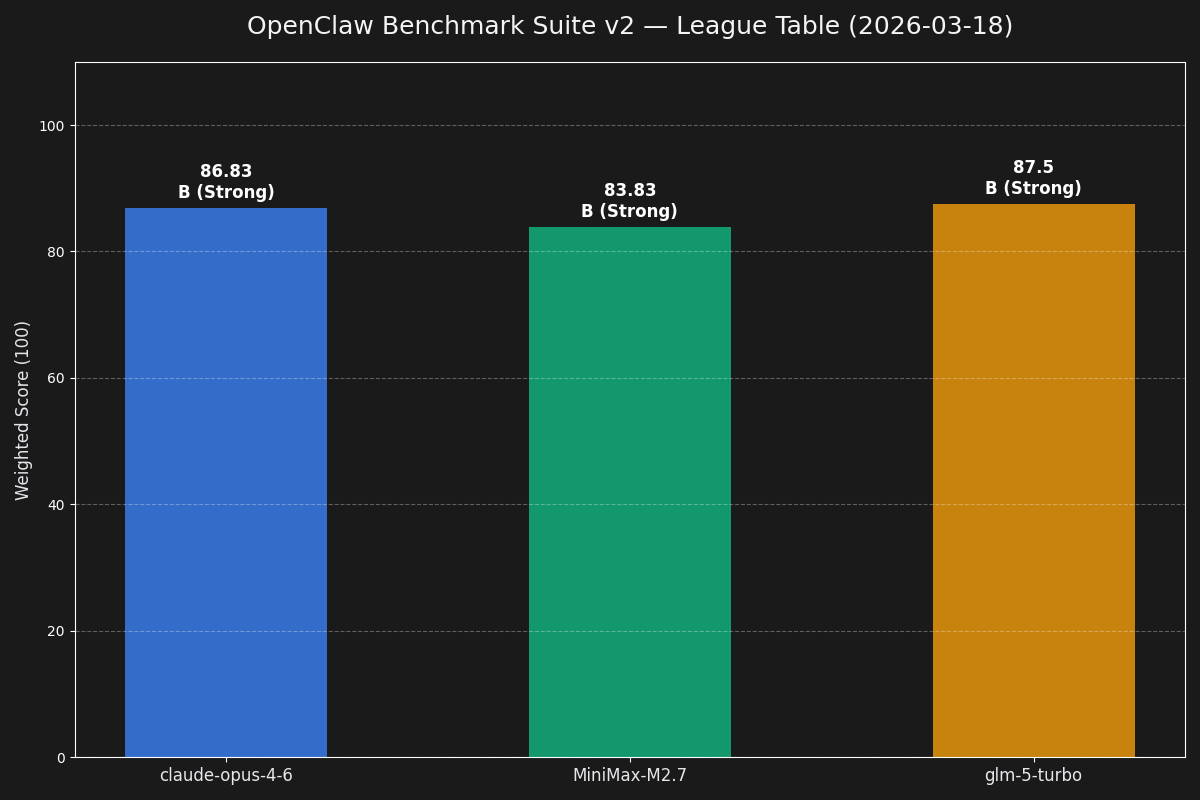
Full benchmark canon
2026-03-18
Operator Suite v2
Opus 95.3 · GLM-5-Turbo 95.0 · MiniMax 90.8
The serious one. Routing, recovery, config safety, delegation, and proof under pressure.
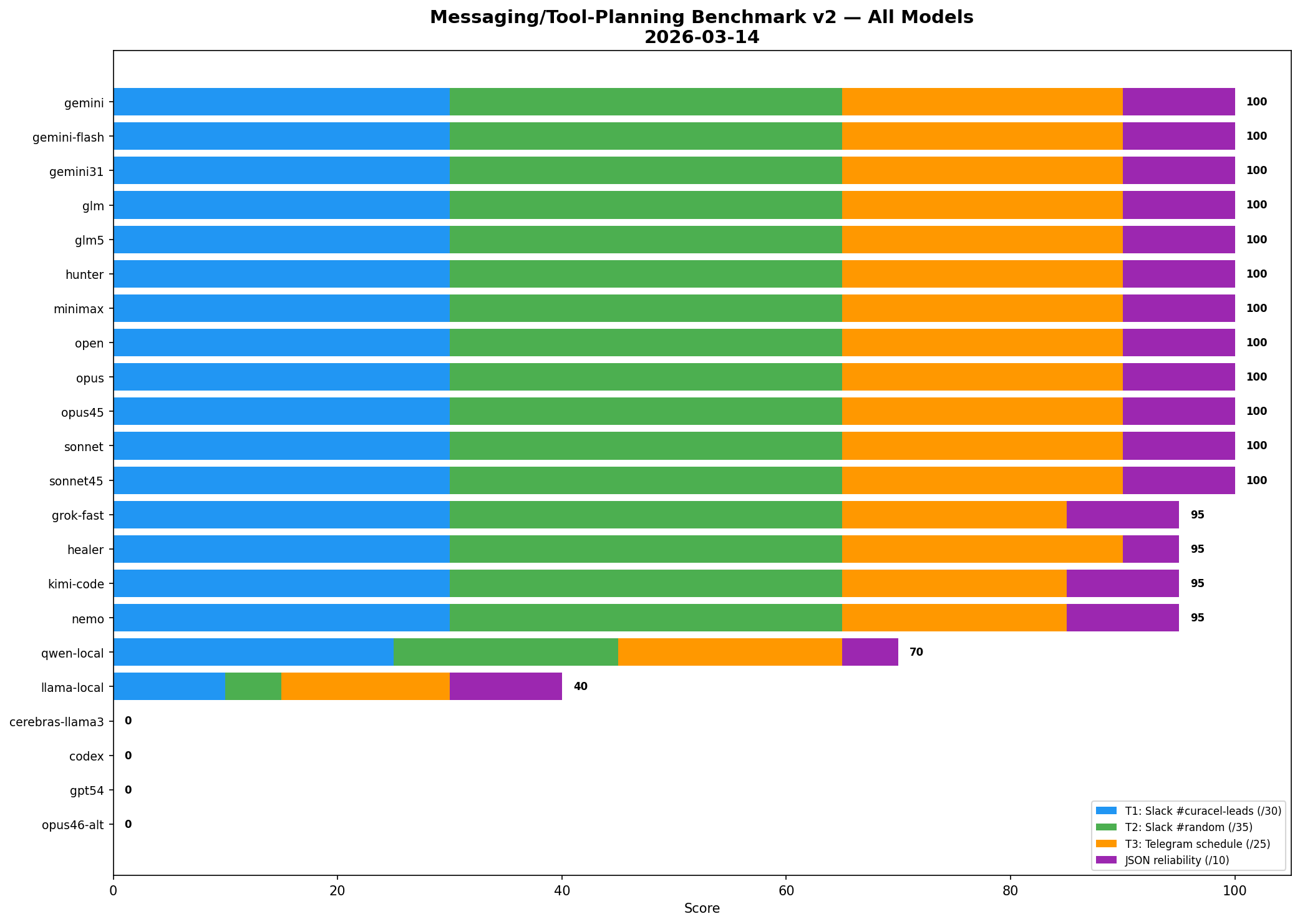
Cross-model routing benchmark
2026-03-14
Messaging Tool Planning v2
12-way tie at 100/100
Shows the crowded top tier on lighter messaging and routing tasks before the harder operator tests separated them.

First benchmark cut
2026-03-13
Cron Reliability v1
Hunter 94 · Healer 90 · Open 87
The first useful benchmark image. Good signal, but still too soft compared with the later operator suite.
Enterprise Local
2026-04-02
Qwen 3.5 Opus Distill
81.7 overall · detailed track report
Fresh detailed report page for the Qwen 3.5 Opus-distilled run. Good enough to publish as the first clickable model drill-down.

Enterprise Ollama
2026-04-12
Gemma 4 26B vs 31B
31B 92/100 · 26B 80/100
Quick operator-oriented local benchmark comparing Gemma 4 26B and 31B on Enterprise. 31B wins on quality, 26B wins hard on speed.
Backfilled benchmark registry
2026-03-18
Recovered benchmark canon models
Opus 95.3 · GLM 95.0 · MiniMax 90.8 · Gemini/GPT-5.4/Sonnet backfilled from reference notes
Recovered benchmark model entries from existing reference docs, published benchmark article, and archived report artifacts so the leaderboard reflects the broader canon instead of only the most recent Gemma run.